
The Modern Data Stack Explained: Components and Benefits
The death of third-party data and surge in cloud computing have led to the rise of the modern data stack (MDS).
In the past, companies had databases in physical servers on-premises as cloud computing was cost-prohibitive. This wasn’t easy to scale. These companies had teams of data analysts and engineers who managed their legacy systems.
As the price of cloud computing has fallen, companies now have the opportunity to use cloud-based tools to gather all of their event streams into a data warehouse for loading and transformation. The intuitive nature of cloud-based tools means you can integrate all tools, from marketing platforms to CRMs, experimentation tools, and analytics — all of them depositing data in one place where you can make sense of the entire data set and finally unlock global data-driven decisions. This democratization of data means business decisions are made faster by different teams, without relying on anyone else.
In this article, we’ll deep dive into:
- What exactly is the modern data stack?
- The components of the MDS.
- Its benefits and limitations.
- What to look for when building your MDS.
- What makes the MDS different from legacy data stacks?
- How the MDS can supercharge experimentation in your company.
What is a modern data stack?
The modern data stack (MDS) is a collection of cloud-based tools designed to help you efficiently and quickly collect, store, process, and visualize data.
The affordability of cloud computing has largely driven the popularity of the MDS. Companies now have a more affordable and flexible way to store, transform, and manage data compared to how data stacks worked in the past.
Components of a modern data stack
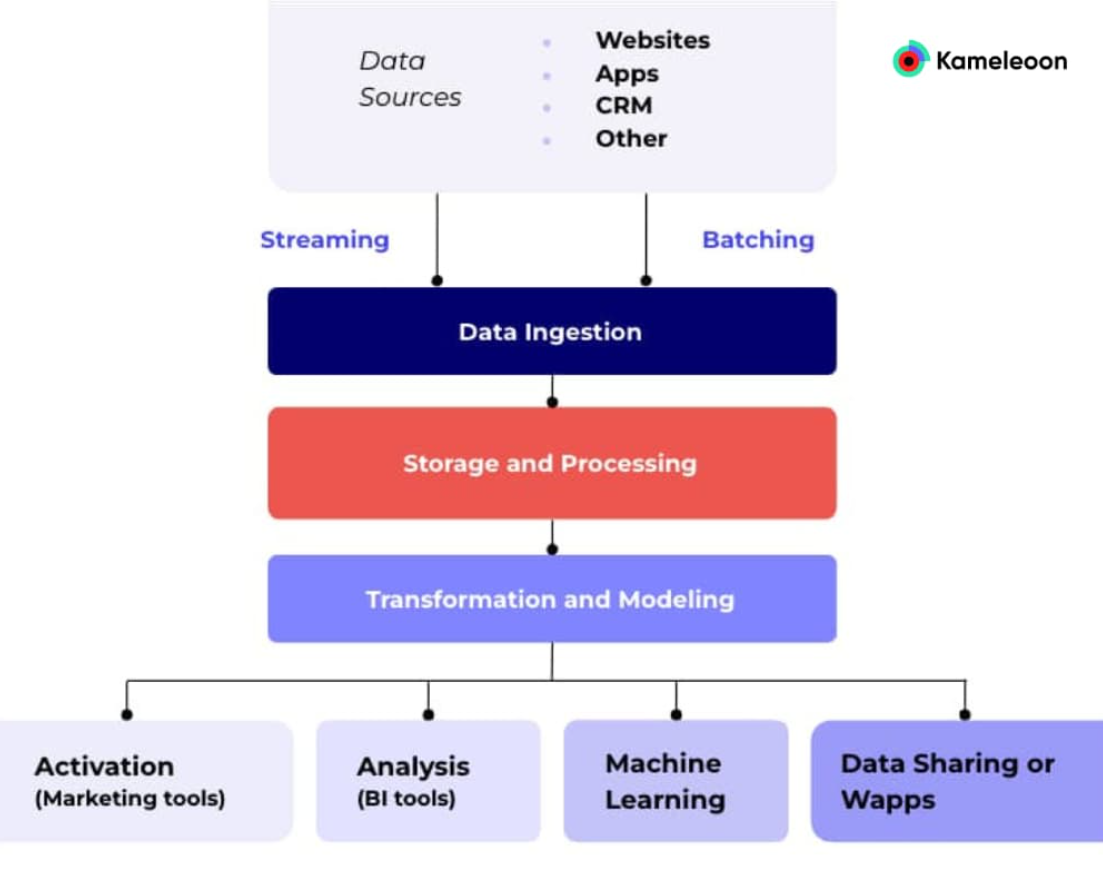
Each component of the modern data stack is made up of different tools depending on their specific tasks. For example, your company has different tools that generate raw data. These different tools all make up the data sources layer of your MDS.
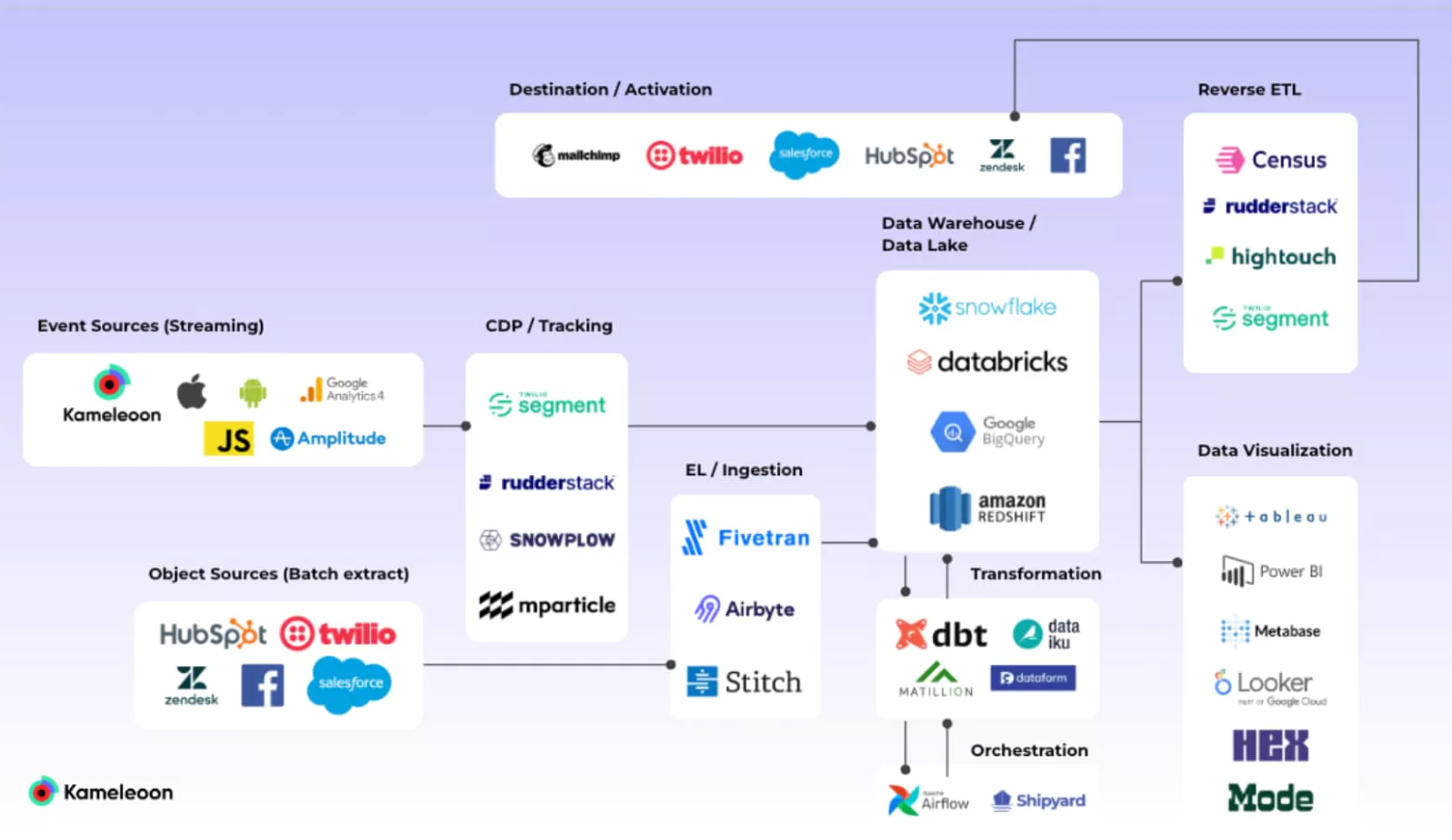
Data sources
Data sources are where all of your data originates. On average, a company pulls data from 400 sources. These sources generate massive amounts of raw data that must be extracted, loaded, and transformed (ELT) for your business. ELT is the data integration method used in the MDS.
Your data sources include both internal and external sources. Your customer relationship management (CRM) software, databases, website analytics, payment platforms, A/B testing tool, and event streams are some of the common data sources.
Data integration
The data integration layer in the modern data stack architecture pulls data from all your event streams and puts them in one place, like a data warehouse, for storage. This gives you a complete overview of all your data.
There are two approaches to extracting, loading, and transforming data for your business:
- ETL: Stands for extract, transform, and load. Traditional data stacks typically use this approach where data is extracted from different sources, transformed into a standard format, and then loaded into a central dashboard.
- ELT: Stands for extract, load, and transform. This approach is more commonly seen in modern data management systems. Data is first extracted from all data sources and loaded into a data warehouse before it is transformed within the warehouse.
Tools like Stitch and Apache NiFi offer connections to data sources, while tools like Apache Kafka can process data in real-time within your data warehouse.
Data storage
After you have collected data from both internal and external streams, the data needs to be stored in a central place where it can be processed and accessed. The storage layer of your modern data stack architecture is where you find data warehouses and data lakes.
Cloud-based data warehouses, like Google BigQuery, Snowflake and Amazon’s Redshift, and lakehouses, like Databricks, are central to the modern data stack. Their analytics capabilities allow access to the data stored in them.
Data transformation and analysis
For all the data you have collected to be valuable, it needs to be analyzed and turned into a comprehensible structure. The tools in this component layer transform and process raw data into a format that can be used by anyone in your organization.
Data transformation can include any of the following:
- Cleaning the data to remove inaccurate or irrelevant entries
- Normalizing the dataset by organizing it into a standard format
- Filtering the data by choosing a segment of it for further consideration based on different criteria
- Summarizing the data to create a compact overview of the dataset by grouping it based on certain criteria.
Tools like dbt and Dataform are crucial for transforming your raw data into a user-friendly format that anyone in your company can use.
Data use and visualization
The goal of the MDS is to centralize data from all your sources into a single repository and activate it with marketing tools or perform analysis with dataviz or business intelligence (BI) tools. This helps you make better business decisions.
Using tools like Tableau, you can create reports and visualization dashboards to understand trends in the data and make decisions based on data-driven insights. Another way to use the data is to build predictive models to automatically forecast trends that steer business decision-making.
Data governance
Data governance is an important part of the modern data stack architecture, including data privacy, security, quality, and compliance.
A cross-functional team creates data governance guidelines and policies for your organization. These policies control how data is managed, who can access it, and ensure compliance with data standards. Tools like Atlan and Egnyte help you ensure that data is handled appropriately within organizations.
What is the difference between a modern and a traditional data stack?
Unlike the cloud-based MDS, traditional data stacks are often on-premise integration of software and hardware managed by your company.
But this isn’t the only difference between the two types of data stacks. Other differences include:
Modularity
MDS allows you to switch tools and platforms in your data infrastructure without much disruption. This flexibility prevents your company from being bound to one vendor — you can change from one vendor to another depending on your needs.
On the other hand, changing components in a traditional data stack is much harder. Because of the hardware and vendors involved, changing one element in your legacy data stack takes time, effort, and considerable budget to avoid any interruption in your data architecture.
Data storage
Traditional data stacks store data in servers that are on the premises or private cloud of your business. Usually, a specific team manages the data infrastructure and is responsible for getting answers to specific data queries to others in the company.
With the MDS, data is stored in servers owned by the vendors in your data storage layer. These vendors have engineering teams to manage their data architecture. Because storage is cloud-based, data democratization is easier, and different teams will use the data as needed.
Data democratization
In an MDS setup, access to data is available to individual members of your organization. While analysts modify the data, individual members of the company are taught how to query, understand and use the data.
This gives both technical and non-technical teams access to all the data your company collects to inform decisions about customers, marketing campaigns, sales, and product features. This increased access to data increases your ROI on business activities.
In a traditional data stack, direct access to data is limited to a few select people. To access insights, individual teams make requests of analysts and engineers who manage the data infrastructure. The data management team spends time modifying the data into understandable forms for non-technical stakeholders. This takes the data management team away from critical work like scaling your data pipelines.
Cost
Due to its cloud-based nature, the costs associated with the MDS are significantly lower than those of traditional data stacks. The lack of specialized hardware and manpower lowers the costs of your data stack considerably. On the other hand, while leveraging MDS you tend to store more data and use computation extensively which can run up costs.
This extra cost pales in comparison to the ROI you get from a single data repository that fuels your knowledge of your audience, product, sales processes as well as the ROI from targeted campaigns your company runs.
The cost of setting up and maintaining a traditional data stack is high. It requires specialized hardware and resources for set-up and maintenance.
Benefits of using a modern data stack
While affordability has driven the adoption of the MDS, it is not the only benefit you get when using this data stack.
Increased efficiency
The slow decision-making associated with legacy data stacks is not present in the MDS as it is more efficient and streamlined.
With MDS, different teams have access to all the data sources your organization generates. They can make decisions informed by deeper knowledge of your customers, product and sales cycle. This democratization of data leads to faster insights and increased efficiency for your business.
Scalability
As your business grows, so do your data needs. With the MDS, you can upgrade the components of your stack to meet your data needs at every stage of business growth.


Upgrading and downgrading your data system to meet your exact data demands is easier with the MDS.
Fast setup time
Setting up your modern data stack tools is fast and easy. You can go from no stack to a fully operational modern stack in as little as an hour. The tools that make up your data stack are typically self-serve, so you can set them up within minutes.
Cost-effective
Using a modern data system eliminates the need for expensive hardware and complex infrastructure. This makes it more cost-effective to set up and operate a cloud-based data stack.
Improved culture around data
The modern data management system is designed to democratize access to data within organizations. Non-technical roles within organizations can now access and place data requests. This increases the proliferation of data within organizations and creates a culture where data is used to inform decisions, tests, products, features, and design.
Limitations of a modern data stack
While there are many benefits to using the modern data stack in your organization, there are some limitations you need to consider.
High upfront costs
Once set up, the MDS is typically cheaper than traditional data stacks. But it requires significant upfront costs to set up.
This limits the use of modern data stacks to companies that can afford to shoulder the initial investment required to set it up. The upfront costs may prevent some companies from using the MDS.
Using open-source tools reduces the upfront expenses of setting up a modern data stack for the first time.
Steep learning curve
The modularity of the modern data stack comes with a steep learning curve for those who are unaccustomed to working with data.
While modularity makes the MDS flexible, it adds a layer of complexity. This complexity becomes obvious when switching vendors. Teams must learn how to use a new tool and how it fits into your existing stack.
Consistent training and comprehensive setup guides help you reduce the time it takes for your team to learn new tools introduced into your stack.
Lack of rigor in data quality
The MDS has created a distance between engineers who manage the data architecture and the different teams who use the data. This distance leads to engineers not understanding why the data is important, who uses the data and how the data is used.
This lack of understanding leads to engineers changing data to meet operational needs without consulting other users of the data who need the data to remain unchanged.
This miscommunication leads to a lack of trust in the data quality. Teams using the data encounter errors as the change in the data was not communicated to them.
To prevent issues with data quality, you need a better focus on data governance and quality. Data contracts can be helpful in mitigating these issues.
A data contract is an agreement between the engineers who manage the data architecture and the teams who understand the business and need quality, well-modeled data for decision-making.
Vendor issues affect your company
With the modern data stack, you never have to worry about a burst pipe in your data centers. But this doesn’t mean you are immune from downtime or disruptions.
Since the tools that make up your stack are provided by external vendors, their problems affect your company. When your vendor experiences an issue, it will affect how your team can access, store, and use data.
For example, if your data warehouse provider experiences content delivery network (CDN) issues or security breaches, your ability to continue using the tool will be disrupted.
Creating local redundancies helps you avoid disruptions from your vendor. Storing your most important data locally can help reduce any downtime or loss of access.
What to consider when building a modern data stack
Building a modern data stack can be difficult as there are thousands of software and service options geared towards every component of the MDS. Before you jump into research, here are a few issues to consider:
Your business needs
Because your business needs are unique, the tools you need in your modern data stack architecture will be too.
Consider what you want to achieve before you research vendors and tools. Do you want to forecast trends in your industry better? Optimize user experience? Your business goals should determine the type of tools that make up your MDS.
In addition to your business needs, set a budget, as the tools in your stack can become costly. If you find yourself running out of budget, look at open-source tools to reduce the financial burden.
User-friendliness
The tools in your data stack should be intuitive and easy to use. When evaluating software for your stack, look for tools that are easy to use and have extensive customer support documentation for when problems arise.
Complicated software may hinder your data democratization efforts as it is difficult to learn. If members of your team are frustrated with a tool, they are less likely to use it. Ensure the tools in your stack are easy to use.
Ability to future-proof
When evaluating tools, it is imperative that the software you choose can grow with your business. As your company grows, your ELT tools need to keep up with increased data demands.
When your data demands outpace the tools’ abilities, your team will struggle with using them to accomplish typical tasks. A tool that grows with your business is paramount.
Security and compliance record of vendors
When dealing with data, security and compliance are of utmost importance. This extends to the modern data stack.
Depending on the type of data and location where you gather the data, your company and the tools you use need to comply with regulations. For example, if you have to handle medical data from the United States, your organization and all of the tools it uses must be HIPAA-compliant. If you are gathering data from European customers, you need to comply with GDPR.
When considering tools to build your MDS, ensure that the software vendors are compliant with relevant data privacy and security laws in your location. Since every vendor may not be licensed in every region, use vendors licensed in your location and that of your customers.
How the modern data stack can fuel your experimentation
MDS is here for the long run. It has changed how companies approach data and in turn, experimentation.
With the MDS, your product teams can get more granular with their experiments. Because you can combine data from different streams in your data warehouse, you can find more areas ripe for optimization. You can combine behavioral, commercial and analytics data to uncover areas to research and optimize.
Timo Dechau, Product and AWS Architect for internal services at Audible, and the founder and Tracking Analytics Engineer at Deepsky Data, expounds on this in his expert interview about Google products used in the modern data stack. He said:


Another benefit offered by the MDS is the ability to create more detailed user segmentation for experiments and other business needs. A small caveat here is that you will have to sacrifice speed for better knowledge of your customers.
“With the MDS, you can enrich the user data with data coming from CRMs, customer success, or customer support tools. This gives you new ways to design experiments with deeper segments.” Dechau concurs.
Since you can combine user data from different data streams, you can build user segments that are more specific and true to your actual customers. This enhances the results and data you get from your experiments.
To get started with a powerful experimentation platform that fits into your modern data stack, book a demo with us.



