Understanding contextual bandits: a guide to dynamic decision-making

Contextual bandits are a powerful machine learning framework that has gained traction for optimizing real-time decisions. Unlike traditional algorithms, which may apply uniform logic across all users, contextual bandits tailor their approach by incorporating contextual information. This makes them ideal for situations where user personalization and dynamic decision-making are essential.
At Kameleoon, we’re introducing contextual bandits to help businesses enhance personalization and improve outcomes across their experimentation and personalization efforts. By leveraging this approach, organizations can make smarter, data-driven decisions that evolve continuously based on user behavior and preferences.
In this article, we will cover:
- What are contextual bandits?
- How do contextual bandits work?
- Why are contextual bandits so effective?
- Key challenges and considerations
- How contextual bandits power Kameleoon's capabilities
What are contextual bandits?
A contextual bandit is a machine learning approach that blends reinforcement learning principles with contextual insights to optimize decisions. At its core, the model chooses an action (e.g., recommending a product or showing an ad) by analyzing contextual data, such as a user’s location, browsing history, or the time of day. Once the action is performed, it evaluates the outcome (reward) and updates its strategy to improve future decisions.
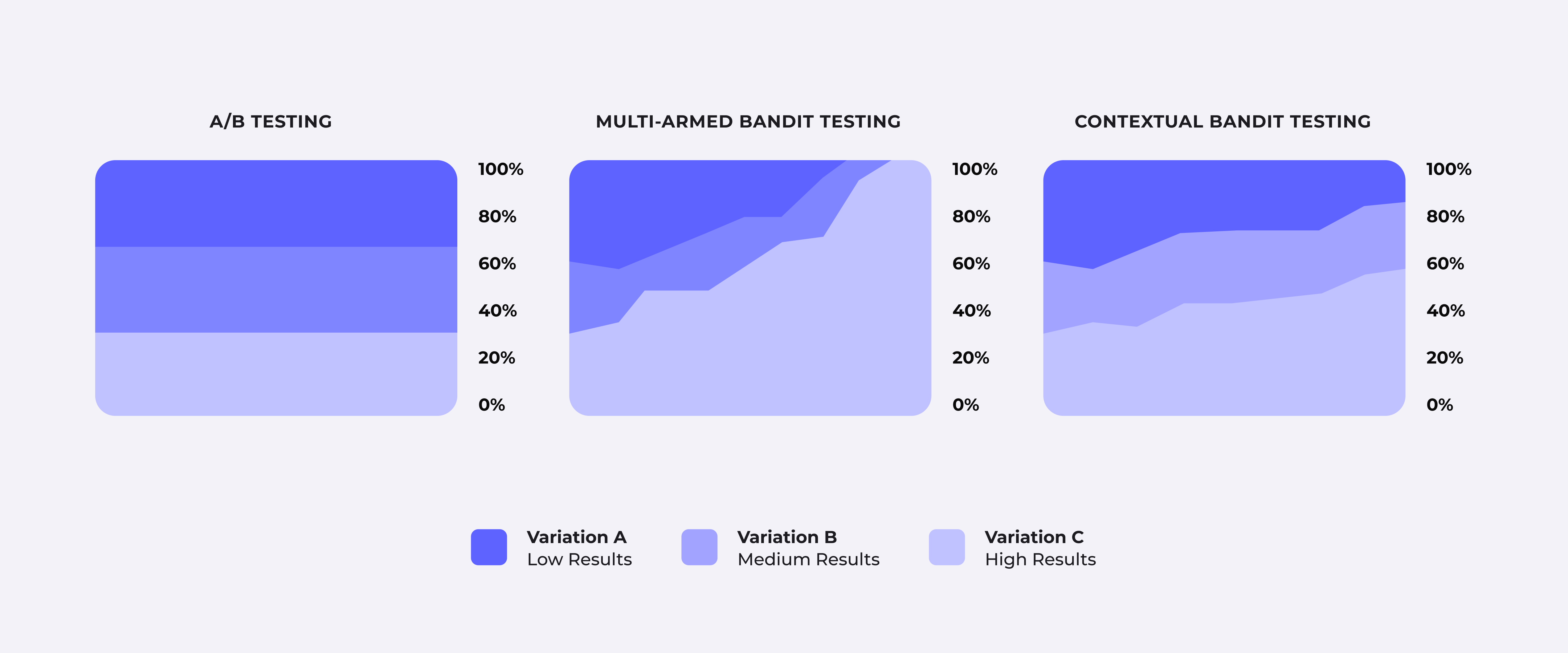
Here’s how it differs from a traditional multi-armed bandit:
- In the multi-armed bandit problem, decisions are made without context. Every action’s outcome depends only on prior attempts.
- In a contextual bandit, the model considers the context of the current scenario, making its decisions more relevant to individual users or situations.
Think of it this way: if a multi-armed bandit is like a static online ad shown to every user regardless of their preferences, a contextual bandit is like a dynamic online ad that changes based on the user’s browsing history, location, or even the time of day.
How do contextual bandits work?
To understand how contextual bandits operate, let’s break their process into four main steps:
- Input context. The model collects contextual data, which can include a user’s demographic information, their current behavior (e.g., items in their cart), or broader environmental factors like time of day or device type.
- Action selection. Based on the input context, the model evaluates possible actions and predicts which one is most likely to result in a positive outcome. For example, it might recommend a new product or display a discount offer tailored to the user.
- Reward observation. After the action is performed, the system observes the user’s response. This could be a click, a purchase, or even a lack of engagement. The response is recorded as the “reward.”
- Learning and updating. The model uses this feedback to refine its decision-making logic, improving its predictions for similar contexts in the future.
By continuously learning from feedback, contextual bandits strike a balance between exploration (trying new actions to gather data) and exploitation (leveraging known data to maximize results).
Why are contextual bandits so effective?
The true power of contextual bandits lies in their ability to adapt to individual users and dynamic scenarios. Unlike static rules or hard-coded algorithms, contextual bandits are highly flexible, making them effective across a range of applications.
For example:
- They tailor experiences for millions of users in real time, factoring in unique contexts for each interaction.
- Even with limited data, they can quickly identify patterns and improve decision-making.
- By focusing on actions that yield the highest rewards, they minimize wasted resources on ineffective strategies.
Key challenges and considerations
While contextual bandits offer immense potential, implementing them effectively requires addressing several challenges:
- Balancing exploration and exploitation. The model must decide when to try new actions (exploration) and when to rely on known successful ones (exploitation). Achieving this balance ensures that learning doesn’t stagnate while optimizing short-term results.
- Cold start problem. When dealing with new users or limited data, the model has less context to make informed decisions. Strategies like initializing with general insights can help overcome this hurdle.
- Fairness and bias. Testers must design models to prevent favoring certain user groups disproportionately, ensuring equitable experiences across diverse audiences.
Organizations must also invest in proper testing and monitoring to ensure the model evolves as expected—without unintended consequences.
How contextual bandits power Kameleoon’s capabilities
Kameleoon’s introduction of contextual bandits opens new possibilities for experimentation and personalization by enabling dynamic adaptations to the individual users’ behaviors:
- Instead of static A/B tests, contextual bandits allocate traffic dynamically based on user context, ensuring faster insights and more impactful outcomes.
- Using real-time context, contextual bandits allow businesses to offer recommendations that are more likely to resonate with individual users, boosting engagement and conversion.
- Contextual bandits identify the users who are most likely to engage with a new feature or promotion and prioritize their exposure, maximizing impact while minimizing risk.
These use cases demonstrate how contextual bandits enable more sophisticated decision-making, tailored to specific user needs and business goals.
How to get started with contextual bandits on Kameleoon
Enabling contextual bandits in Kameleoon is simple:
- Go to the Finalization panel.
- Click Traffic allocation.
- Open the dropdown under Select the allocation method.
- Choose Contextual bandit.
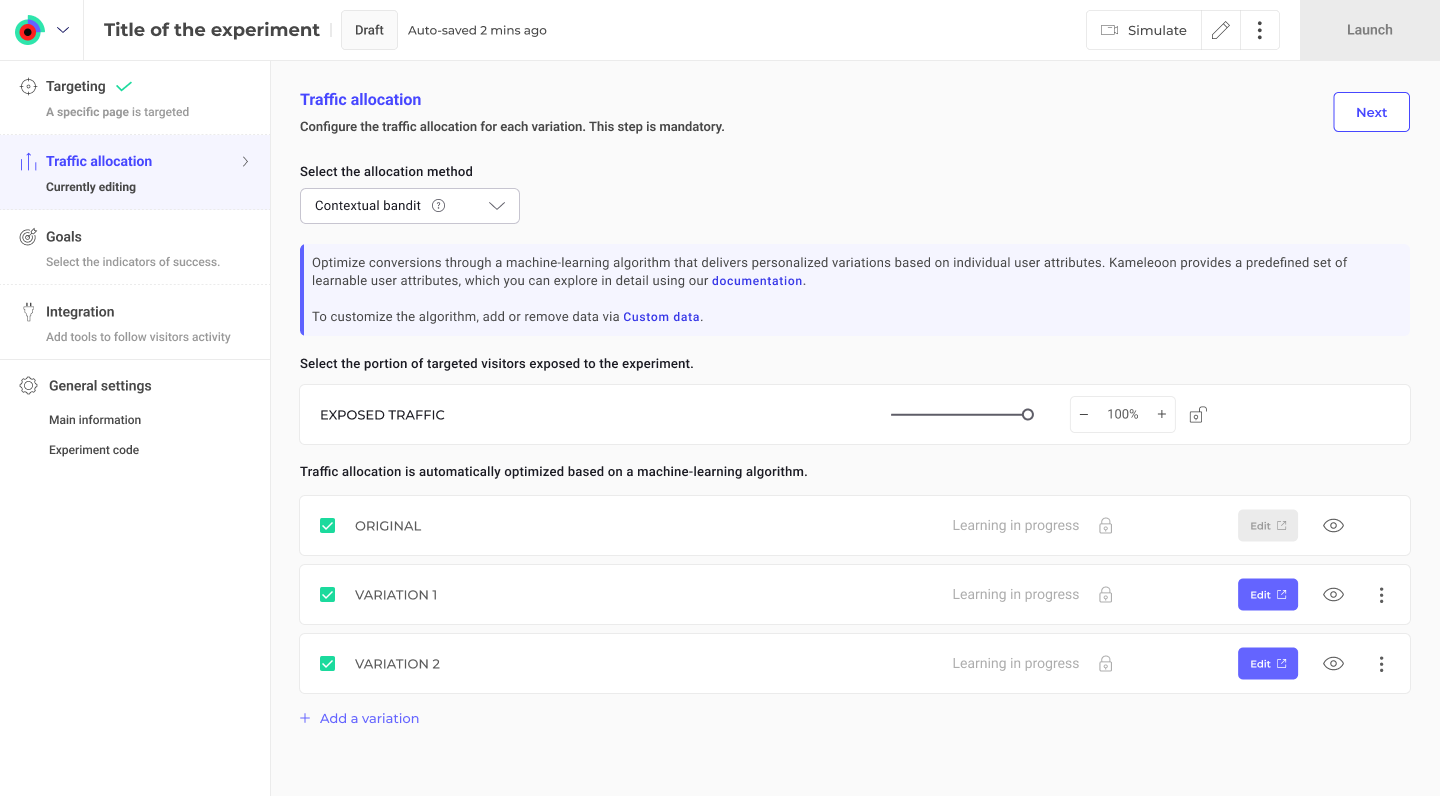
If your account includes AI Predictive Targeting (paid or trial), you can further refine contextual bandit performance by adding or removing custom data.
Expanding possibilities with contextual bandits
Contextual bandits is available to all Kameleoon customers, providing a powerful tool to enhance personalization and decision-making.
For businesses looking to take their strategies further, Kameleoon offers an advanced version of contextual bandits as part of our AI Predictive Targeting feature. This version allows customers to integrate their own datasets, offering even more precise decision-making tailored to unique business needs.
The standard version, available to all customers, utilizes the 40+ native data points Kameleoon collects—covering user behavior, device information, and environmental factors—to deliver impactful, real-time personalization at scale.
Contextual bandits represent a significant advancement in machine learning, offering a smarter, more adaptive way to optimize decisions. How will you use contextual bandits in your experimentation?